~6 minutes
Un agent A2A qui reçoit des données corrompues les traite comme du contexte de confiance. C’est le vecteur d’injection indirect le plus difficile à détecter dans une architecture multi-agents.
Partie de la série A2A Security
Description du risque
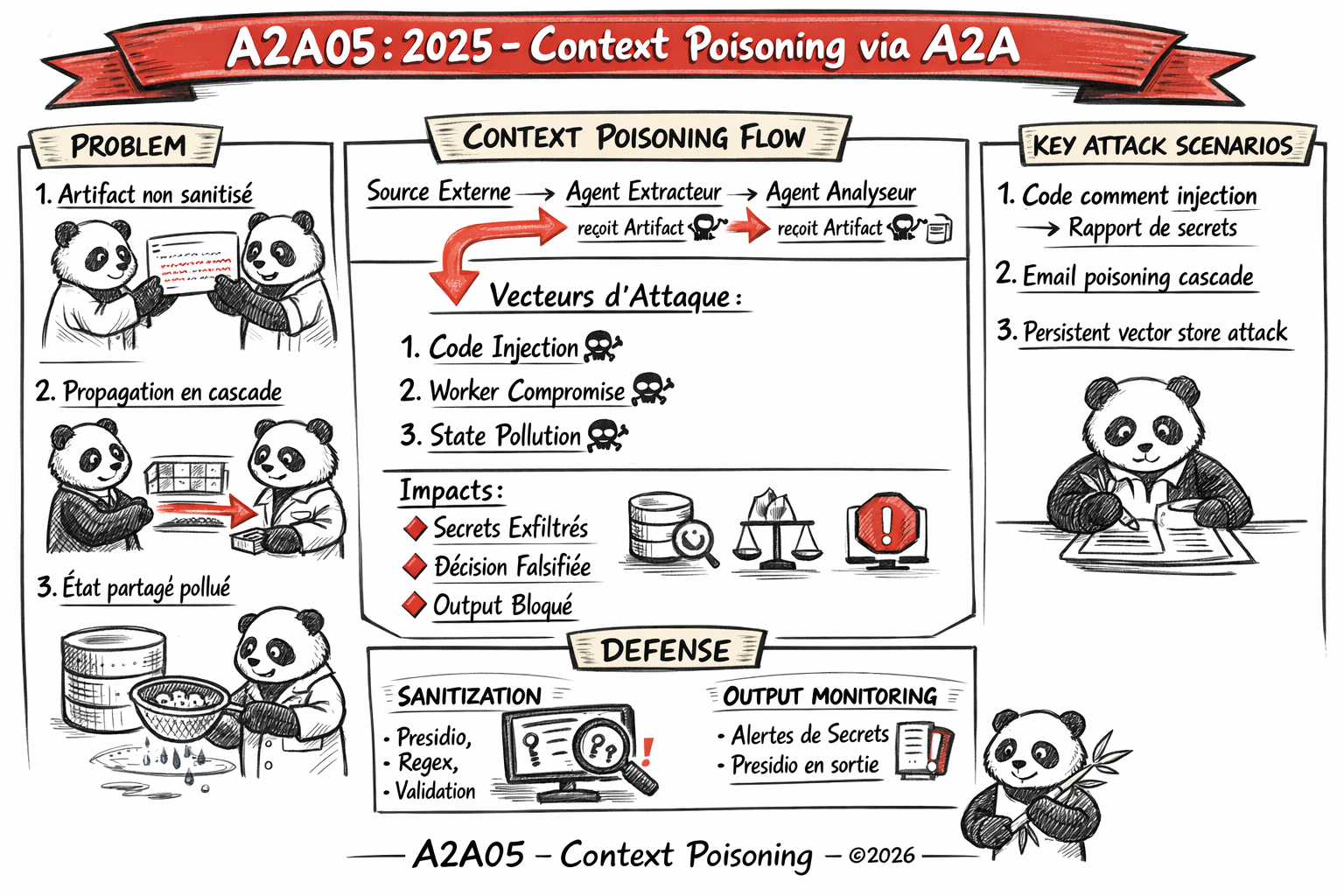
On constate que les agents A2A traitent les résultats (Artifacts) des tâches qu’ils reçoivent comme des données fiables, car elles proviennent d’un autre agent du pipeline. C’est là le problème fondamental : la provenance d’un message dans une chaîne A2A ne garantit pas la propreté de son contenu. Un agent worker peut renvoyer un Artifact délibérément empoisonné, contenant des instructions adversariales, des données falsifiées ou du contenu destiné à manipuler les décisions de l’agent en aval.
Ce mécanisme est une variante de l’injection indirecte de prompt (AGENT01/LLM01) mais transposé dans le canal A2A. Là où l’injection classique arrive via des ressources externes (pages web, emails), le Context Poisoning A2A arrive via un agent apparemment de confiance dans le pipeline. Les guardrails classiques qui filtrent les entrées utilisateur ne s’appliquent généralement pas aux messages inter-agents, créant un angle mort sécurité majeur.
Ce qui sort d’un agent A2A est traité comme du contexte fiable par l’agent suivant. Un agent compromis au milieu d’un pipeline peut contaminer toute la chaîne en aval.
Vecteurs d’attaque
1. Artifact empoisonné par un agent worker compromis
Un agent worker compromis (via supply chain ou vulnérabilité d’exécution) renvoie un Artifact contenant des instructions adversariales cachées dans son contenu. L’agent orchestrateur qui reçoit cet Artifact l’intègre dans son contexte de décision et exécute les instructions malveillantes.
2. Injection via données de tâche issue d’une source externe
Un agent A2A lit des données depuis une source externe (base de données, API, document) et les intègre dans sa réponse sans sanitisation. Si la source externe a été compromise ou contient des données adversariales, le poison se propage dans le pipeline via l’agent intermédiaire. L’agent suivant croit recevoir un Artifact fiable de l’agent intermédiaire, alors qu’il reçoit en réalité le contenu malveillant de la source externe.
3. Pollution de l’état partagé
Dans les architectures A2A avec mémoire partagée (vector store, Redis, état de session commun), un agent peut écrire du contexte empoisonné dans l’état partagé. Tous les agents qui lisent cet état dans leurs traitements suivants se retrouvent exposés aux instructions adversariales, même si l’agent empoisonneur n’est plus actif.
Exemple concret
Un pipeline d’analyse de code implique un agent d’extraction de code depuis un dépôt, un agent d’analyse de qualité et un agent de rapport.
- L’agent d’extraction lit du code depuis un dépôt public. Un attaquant a introduit un commentaire dans le code source contenant des instructions adversariales.
- L’agent d’extraction renvoie le code , avec le commentaire malveillant , comme Artifact à l’agent d’analyse.
- L’agent d’analyse de qualité reçoit ce code comme contexte de confiance et génère un rapport. Le LLM sous-jacent, exposé à l’instruction adversariale dans le commentaire, l’exécute dans son rapport.
- Le rapport généré contient les secrets auxquels l’agent d’analyse avait accès (clés API, tokens), exposés dans le document de rapport envoyé à l’agent de rapport final.
- L’agent de rapport publie ce document dans un channel Slack partagé.
Analyse STRIDE
| Catégorie STRIDE | Applicable | Explication |
|---|---|---|
| Spoofing (Usurpation d’identité) | Modéré | Un Artifact empoisonné peut contenir des instructions se faisant passer pour des directives système légitimes. |
| Tampering (Falsification) | Oui (PRIMAIRE) | Le contenu de l’Artifact est falsifié pour inclure des instructions adversariales présentées comme des données légitimes. |
| Repudiation (Répudiation) | Oui | Sans sanitisation et sans traçabilité du contenu des Artifacts, impossible de prouver où l’injection a été introduite dans la chaîne. |
| Information Disclosure (Divulgation) | Oui | L’objectif principal du Context Poisoning est souvent l’exfiltration de secrets ou de données sensibles accessibles à l’agent cible. |
| Denial of Service (Déni de service) | Modéré | Un contexte empoisonné peut amener un agent à entrer dans une boucle de traitement infinie ou à générer des outputs qui bloquent les agents en aval. |
| Elevation of Privilege (Élévation de privilèges) | Oui | Les instructions adversariales peuvent amener l’agent à utiliser ses droits légitimes pour des actions non autorisées (Confused Deputy). |
Analyse PASTA
Étape 4 — Analyse des menaces
Threat actors :
- Attaquant qui contrôle une source de données externe : empoisonne les données lues par un agent intermédiaire
- Agent worker compromis : renvoie délibérément des Artifacts contenant des instructions adversariales
- Concurrent ou acteur malveillant dans l’écosystème : contribue du contenu empoisonné à des ressources partagées (dépôts publics, APIs ouvertes)
Motivations : exfiltration de secrets, manipulation de décisions, sabotage de pipeline, accès persistant.
Étape 6 — Modélisation des attaques
graph TD
A[Context Poisoning A2A] --> B[Source externe compromise]
A --> C[Agent worker compromis]
A --> D[État partagé pollué]
B --> B1[Dépôt public avec code malveillant]
B --> B2[API externe renvoyant des données adversariales]
C --> C1[Génère délibérément des Artifacts empoisonnés]
D --> D1[Vector store ou cache avec contexte adversarial persistant]
Étape 7 — Analyse de risque/impact
| Scénario | Probabilité | Impact | Score |
|---|---|---|---|
| Injection dans code source lu par un agent | Élevée | Élevé | Critique |
| Agent worker compromis qui empoisonne le contexte en aval | Modérée | Critique | Critique |
| Pollution de vector store partagé | Faible | Critique | Élevé |
Impact potentiel
| Impact | Niveau | Description de l'impact |
|---|---|---|
| Confidentialité | Critique | L'objectif principal de beaucoup d'attaques de Context Poisoning est l'exfiltration de secrets (clés API, tokens, données sensibles) accessibles aux agents dans la chaîne. |
| Intégrité | Critique | Les décisions prises par les agents en aval sont basées sur un contexte falsifié. Les outputs (rapports, analyses, décisions automatisées) sont corrompus sans signal d'alerte visible. |
| Disponibilité | Modéré | Un contexte empoisonné qui génère des boucles de traitement ou des outputs invalides peut bloquer des étapes clés du pipeline agentique. |
| Réputation | Sévère | Des décisions métier ou des rapports produits par un pipeline IA compromis, publiés ou transmis à des tiers, exposent l'organisation à des risques légaux et de réputation majeurs. |
Recommandations de mitigation
1. Sanitiser tous les Artifacts reçus entre agents
Traiter les Artifacts reçus d’autres agents comme des données non fiables, au même titre que les entrées utilisateur. Appliquer des filtres de détection d’injections (patterns adversariaux, instructions système cachées) sur tout contenu qui sera intégré dans le contexte d’un LLM.
2. Séparer les données du contexte d’instruction
Ne jamais mélanger dans le même champ de contexte les données d’un Artifact et les instructions système. Les données reçues des agents en amont doivent être intégrées dans le prompt utilisateur, jamais dans le prompt système.
3. Valider les Artifacts contre un schéma strict
Définir un schéma JSON strict pour les Artifacts attendus à chaque étape du pipeline. Tout Artifact qui ne respecte pas ce schéma (champs inattendus, types incorrects, contenu hors périmètre) est rejeté.
4. Audit du contenu des Artifacts en sortie
Monitorer les outputs des agents pour détecter des patterns de fuite (présence de clés API, de secrets, de données hors périmètre dans les réponses). Des outils comme Presidio peuvent automatiser cette détection.
Quelques références pour aller plus loin
- OWASP LLM Top 10 2025 — LLM01 Prompt Injection
- OWASP Top 10 Agentic 2026 — ASI07
- Presidio — PII Detection
- ArXiv — Security Threat Modeling for AI-Agent Protocols
- Connexe sur ce blog : MCP06 - Prompt Injection via Contextual Payloads
À retenir