~4 minutes
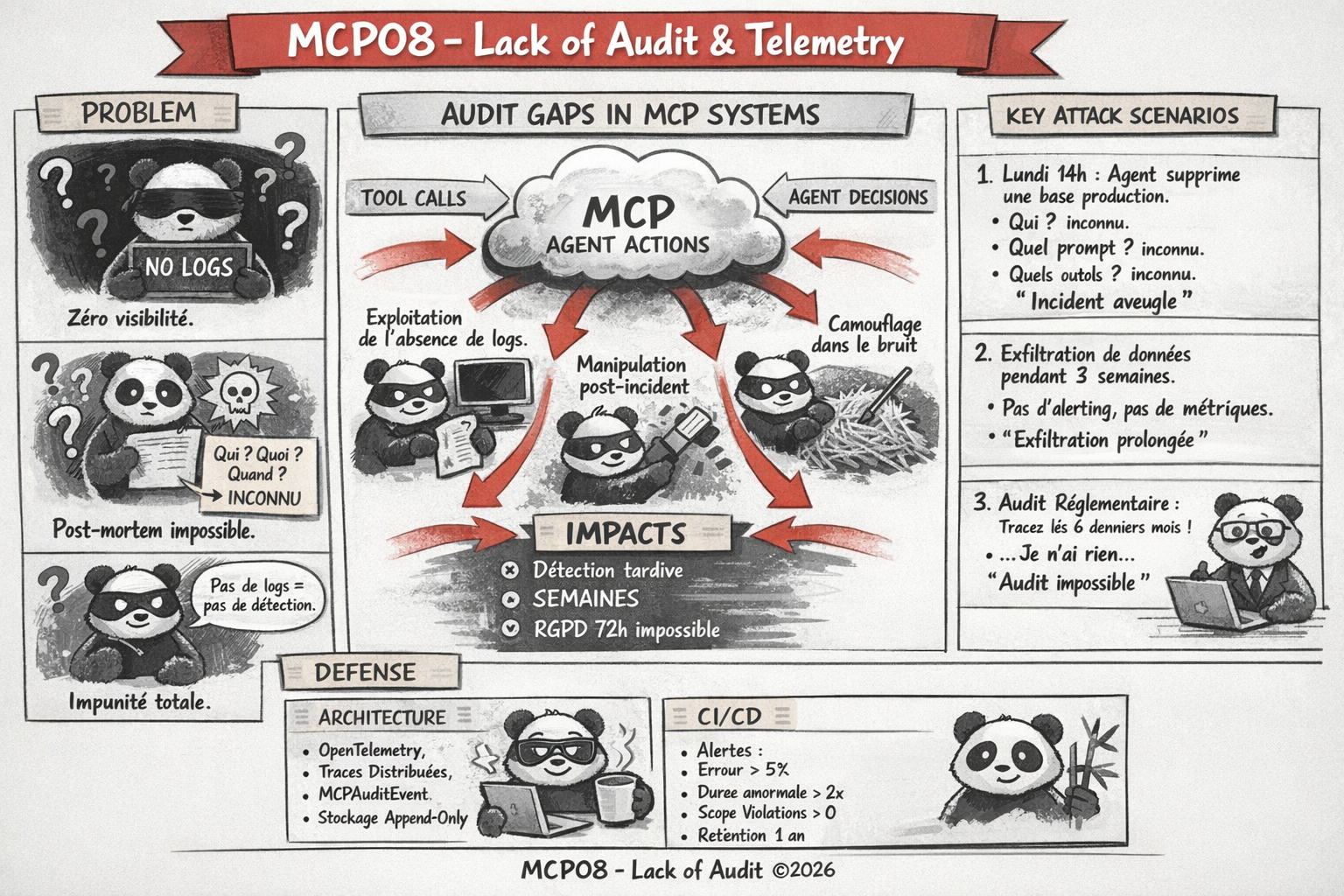
Un agent IA agit, et personne ne sait ce qu’il a fait. Sans logs, sans telemetry, sans traces — quand un incident arrive, tu travailles à l’aveugle. Et dans le monde MCP, les agents peuvent agir à une vitesse que les humains ne peuvent pas suivre sans instrumentation.
Partie de la série OWASP MCP Top 10
Description du risque
Je constate que le manque d’audit est le risque le plus sous-estimé dans les déploiements MCP , et pourtant, c’est celui qui rend tous les autres invisibles.
Le manque d’audit et de télémétrie dans les systèmes MCP impacte directement la capacité d’investigation et de réponse aux incidents. Quand un agent IA prend des décisions autonomes et invoque des outils, sans traces détaillées il est impossible de savoir ce qui s’est passé.
Pas de logs = pas de forensic. Un incident sur un système non instrumenté est un trou noir. Et dans le monde MCP, les agents agissent trop vite pour le suivi humain.
Ce risque est particulièrement aigu car :
- Les agents enchaînent des dizaines d’appels d’outils en quelques secondes
- Les décisions sont prises par le modèle, pas par du code déterministe
- Le “pourquoi” d’une action nécessite de capturer le contexte complet
- Les systèmes multi-agents créent des chaînes d’actions très difficiles à reconstituer
Vecteurs d’attaque
On distingue quatre façons dont l’absence de télémétrie est exploitée :
1. Exploitation de l’absence de logs
Un attaquant qui sait que le serveur MCP n’a pas de monitoring agit en toute impunité. Pas de logs = pas de détection, pas de forensic.
2. Manipulation post-incident
Sans logs immuables, un attaquant peut modifier ou supprimer les traces de son passage.
3. Camouflage dans le volume
Si les logs existent mais sans alerting, l’attaquant camoufle ses actions dans le volume normal des appels MCP.
4. Exploitation des gaps de couverture
Les logs couvrent les requêtes HTTP mais pas les appels d’outils MCP internes. L’attaquant utilise les chemins non instrumentés.
Analyse STRIDE
| Catégorie STRIDE | Applicable | Explication |
|---|---|---|
| Spoofing (Usurpation d’identité) | Modéré | Sans audit, le spoofing passe inaperçu. |
| Tampering (Falsification) | Modéré | Sans logs, la falsification de données est indétectable. |
| Repudiation (Répudiation) | Oui (PRIMAIRE) | C’est le coeur du problème. Pas d’audit = pas de responsabilité. Impossible d’attribuer une action à un agent ou utilisateur spécifique. |
| Information Disclosure (Divulgation d’informations) | Modéré | Les fuites de données passent inaperçues sans monitoring. |
| Denial of Service (Déni de service) | Modéré | Les DoS sont détectés tardivement sans alerting. |
| Elevation of Privilege (Élévation de privilèges) | Modéré | L’abus de privilèges est indétectable sans audit des actions. |
Impact potentiel
| Impact | Niveau | Description de l'impact |
|---|---|---|
| Confidentialité | Élevé | Les fuites de données passent inaperçues pendant des semaines ou des mois. Sans détection, le périmètre de compromission s'étend indéfiniment. |
| Intégrité | Élevé | Impossible de détecter les modifications non autorisées de données ou de configurations. L'attaquant modifie en silence. |
| Disponibilité | Élevé | Les incidents sont détectés tardivement. Le temps moyen de détection (MTTD) sans monitoring est mesuré en semaines, pas en minutes. |
| Réputation | Critique | L'incapacité à fournir un post-mortem détaillé après un incident détruit la confiance. Les régulateurs (RGPD art. 33) exigent une notification sous 72h , impossible sans logs. |
Recommandations de mitigation
Structure d’événement d’audit
Je recommande d’instrumenter chaque appel d’outil MCP avec cette structure d’événement d’audit :
from dataclasses import dataclass
from datetime import datetime
@dataclass
class MCPAuditEvent:
timestamp: datetime
session_id: str
agent_id: str
user_id: str | None
tool_name: str
tool_params: dict # Attention : masquer les secrets !
tool_output_summary: str # Pas le contenu complet (RGPD)
execution_duration_ms: int
parent_context_id: str | None # Pour chaînes multi-agents
triggered_by: str # "user_prompt" | "agent_decision" | "scheduled"
status: str # "success" | "error" | "blocked"
error_message: str | None
security_flags: list[str]
Implémentation avec OpenTelemetry
Voici en exemple d’intégration OpenTelemetry dans un serveur MCP :
import structlog
from opentelemetry import trace
logger = structlog.get_logger()
tracer = trace.get_tracer("mcp-server")
class AuditedMCPServer:
async def execute_tool(self, tool_name: str, params: dict, context: dict):
with tracer.start_as_current_span(f"mcp.tool.{tool_name}") as span:
span.set_attributes({
"mcp.tool.name": tool_name,
"mcp.agent.id": context.get("agent_id"),
"mcp.session.id": context.get("session_id"),
})
safe_params = self.redact_sensitive_params(params)
logger.info("mcp_tool_execution",
tool=tool_name, params=safe_params,
agent=context.get("agent_id"))
try:
result = await self.tools[tool_name].execute(params)
logger.info("mcp_tool_success", tool=tool_name)
return result
except Exception as e:
logger.error("mcp_tool_error", tool=tool_name, error=str(e))
span.record_exception(e)
raise
Exemple de métriques d’observabilité
| Métrique | Seuil d’alerte | Action |
|---|---|---|
| Taux d’erreur outils | > 5% | Investigation |
| Durée d’exécution anormale | > 2x médiane | Review |
| Nombre d’appels par session | > 100 | Review humain |
| Scope violation attempts | > 0 | Alerte immédiate |
| Nouveaux outils appelés | Premier appel | Notification |
Stocker les logs dans un système immuable (SIEM, stockage append-only)
Les logs doivent être stockés dans un système immuable pour garantir qu’un attaquant ne puisse pas les modifier ou les supprimer après coup. Par exemple, utiliser un stockage append-only ou un SIEM avec intégrité vérifiable.
Rétention de 1 an minimum pour audit légal
Conformément aux exigences réglementaires (RGPD art. 33), les logs doivent être conservés pendant au moins 1 an pour permettre une investigation complète en cas d’incident.
Tests réguliers de la capacité à investiguer un incident fictif
Il est crucial de tester régulièrement la capacité de l’équipe à investiguer un incident fictif en utilisant les logs et métriques disponibles. Cela permet de valider que les données collectées sont suffisantes pour reconstituer une chaîne d’actions et identifier les causes racines.
Quelques références pour aller plus loin
À retenir