~10 minutes
On parle beaucoup de ce que les agents IA peuvent faire : générer des endpoints REST en trente secondes, refactoriser cinq cents lignes de code legacy en un prompt, écrire des tests unitaires à la volée. Ce qu’on oublie de dire, c’est que cette vitesse est aussi celle à laquelle les vulnerabilités entrent en production.
Le vrai problème n’est pas l’outil utilisé ( GitHub Copilot, Cursor, Windsurf, un Claude, un Codex avec GPT-42) ou n’importe quel autre agent. Le problème, c’est que la chaîne de développement n’a pas été conçue pour ce niveau de débit. Les spécifications restent vagues, la planification est inexistante et la revue de sécurité ne tient plus la cadence.
Je vous propose une approche en trois phases, générique et adaptable à n’importe quelle chaîne qui intègre un agent IA pour écrire du code. Cela n’empéche pas les équipes de continuer à utiliser leurs outils préférés, mais ça impose une structure indispensable pour que la vitesse de l’IA ne devienne pas un risque de sécurité.
L'humain reste au cœur du développement
L'humain reste au centre du processus, mais il doit être assisté par des artefacts clairs et des règles strictes pour que l'IA puisse être un accélérateur de productivité sans devenir un accélérateur de vulnérabilités.
Je ne propose pas de ralentir l'IA, je propose de structurer ce qu'elle reçoit en entrée et ce qu'on vérifie en sortie. C'est la clé pour sécuriser le développement assisté par IA à grande échelle.
Je ne suis pas CONTRE les agents IA qui codent !
Je suis CONTRE les équipes qui les laissent coder sans cadre structuré, sans plan et sans revue rigoureuse leurs agents et outils.
Le vrai risque : la vitesse sans structure
“Un agent IA qui code sans contraintes, c’est un développeur junior très rapide, sans revue de pair, sans spec, et sans équipe sécurité et qui commit directement en main.”
Ce que j’ai observé dans les projets qui adoptent les agents IA sans cadre structuré :
- Les issues GitHub sont rédigées en deux lignes (“ajouter endpoint de login”) → l’agent invente les détails, souvent mal.
- Aucun plan d’implémentation n’est produit avant la génération de code → des fichiers imprévus sont créés, des dépendances rajoutées sans contrôle.
- La revue de code reste “humaine et visuelle” → personne ne mappe les changes à l’OWASP Top 10 systématiquement par exemple, et les findings critiques passent à travers.
La solution n’est pas de ralentir l’IA. C’est de structurer ce qu’elle reçoit en entrée et ce qu’on vérifie en sortie.
Phase 1 : Des spécifications lisibles par une machine
Un agent IA génère du code en fonction du contexte qu’on lui fournit. Si ce contexte est ambigu, le code le sera aussi. La première étape consiste à rendre les spécifications structurées et machine-readable => ce qui bénéficie à la fois à l’agent et à l’équipe.
L’issue template avec champs sémantiques
Que vous utilisiez GitHub Issues, Jira, GitLab Issues ou Linear, l’idée est la même : forcer des champs structurés qui capturent les informations de sécurité dès la création de l’exigence.
Voici un exemple d’issue template GitHub (.github/ISSUE_TEMPLATE/feature_request.yml) :
name: "Feature Request"
description: "Demande de fonctionnalité — avec critères de sécurité"
title: "[FEAT] "
labels: ["feature"]
body:
- type: textarea
id: description
attributes:
label: "Description fonctionnelle"
description: "Que doit faire cette fonctionnalité ? Soyez précis."
validations:
required: true
- type: textarea
id: acceptance_criteria
attributes:
label: "Critères d'acceptation"
description: |
Format Given/When/Then — chaque critère doit être testable.
Exemple :
- Given: utilisateur non authentifié
- When: appel POST /api/resource
- Then: retour 401 avec corps JSON standardisé
validations:
required: true
- type: textarea
id: trust_boundaries
attributes:
label: "Trust boundaries affectées"
description: |
Listez les frontières de confiance traversées par cette fonctionnalité.
Ex: Internet → API Gateway, API → Base de données, Service A → Service B
validations:
required: true
- type: textarea
id: input_output_contracts
attributes:
label: "Contrats d'entrée / sortie"
description: |
Décrivez les données en entrée (types, format, origine) et en sortie.
Précisez les règles de validation attendues pour chaque champ.
validations:
required: true
- type: textarea
id: security_considerations
attributes:
label: "Considérations de sécurité"
description: |
- Authentification requise ? (oui/non, mécanisme)
- Données sensibles manipulées ? (PII, financier, santé...)
- Impacts sur la surface d'attaque ?
- Contrôles OWASP concernés ?
validations:
required: true
- type: textarea
id: testability
attributes:
label: "Critères de testabilité"
description: |
Comment valider le bon fonctionnement ET la sécurité ?
Tests unitaires, intégration, fuzzing, DAST prévu ?
validations:
required: true
- certains vont me dire que cela fait beaucoup de champs à remplir , mais c’est le but ! Plus vous demandez d’informations structurées, moins l’agent doit les inventer lui-même, et plus le code généré sera aligné avec vos exigences de sécurité.
- certains vont me dire que les champs ne sont pas ‘Typés’ et que on ne peut pas faire de validation stricte ! C’est vrai mais l’objectif ici est de forcer une structure sémantique , même si c’est du texte libre, l’agent peut apprendre à reconnaître les sections et à extraire les informations clés. C’est déjà un énorme progrès par rapport à une issue non structurée.
Ce que ça change pour l’agent IA
Quand l’agent reçoit une issue structurée de cette façon, il peut :
- Identifier automatiquement les validations d’entrée à implémenter (même si elles ne sont pas typées).
- Respecter les contracts d’interface définis (pas d’invention).
- Cibler les contrôles de sécurité spécifiés dans la fonctionnalité.
Sans cette structure, l’agent complète les trous lui-même => et il ne complète pas nécessairement avec vos choix de sécurité.
Enforcer les exigences avant entrée en backlog
Pour qu’une issue entre dans un sprint ou un backlog actif, on peut automatiser la vérification de complétude. Toujours suivant l’exemple Github et les éléments précédents, on peut créer un script qui vérifie que les champs obligatoires sont remplis, et si ce n’est pas le cas, labeler automatiquement l’issue needs-security-spec pour indiquer qu’elle doit être complétée avant d’être traitée.
# scripts/validate_issue.py — exemple d'automatisation via GitHub Actions
REQUIRED_FIELDS = [
"Critères d'acceptation",
"Trust boundaries affectées",
"Contrats d'entrée / sortie",
"Considérations de sécurité",
]
def validate_issue_body(body: str) -> list[str]:
missing = []
for field in REQUIRED_FIELDS:
if field not in body:
missing.append(field)
return missing
Ce script peut être déclenché sur chaque création/mise à jour d’issue via webhooks ou GitHub Actions, et labeler automatiquement needs-security-spec les issues incomplètes.
Phase 2 : Du problème au plan — jamais de code sans architecture
C’est la phase la plus difficile à implémenter culturellement, mais la plus impactante. L’agent IA ne doit pas écrire une ligne de code avant d’avoir produit un plan d’implémentation validé.
Le PLANNING_TEMPLATE
Voici un exemple de template de plan d’implémentation que tout agent ou développeur doit produire avant de commencer :
# Plan d'implémentation — [Titre de l'issue]
## Référence
- Issue : #XXX
- Auteur du plan : [IA / Humain]
- Date : YYYY-MM-DD
## Périmètre
Ce plan couvre exactement ce qui est décrit dans l'issue. Toute fonctionnalité
hors périmètre doit faire l'objet d'une nouvelle issue.
## Décisions d'architecture
- Choix techniques retenus et justification (pas d'invention)
- Patterns utilisés (ex: repository pattern, validation layers)
- Dépendances ajoutées (nom, version, raison, licence)
## Changements fichier par fichier
| Fichier | Action | Description |
|---------|--------|-------------|
| app/routers/foo.py | Créer | Endpoint POST /api/foo avec validation |
| app/models/foo.py | Modifier | Ajout du champ `bar` avec contraintes (type, longueur) |
| app/schemas/foo.py | Créer | Schémas d'entrée/sortie |
| tests/api/test_foo.py | Créer | Tests unitaires et d'intégration (pytest) |
## Contrôles de sécurité à implémenter
- [ ] Validation côté serveur (champ X : type, longueur, format)
- [ ] Authentification/autorisation (mécanisme retenu)
- [ ] Gestion des erreurs sans fuite d'information
- [ ] Logging des actions sensibles
## Stratégie de test
- Tests unitaires : couverture des cas limites et cas d'échec
- Tests d'intégration : flux complets avec mocks
- Tests négatifs : injections, payloads malformés
## Points de revue humaine obligatoires
- [ ] Architecture validée avant génération de code
- [ ] Contrôles sécurité vérifiés après génération
- [ ] Revue finale avant merge
## Rollback
- Changements réversibles ? (oui/non)
- Procédure de rollback si déploiement en erreur
Un prompt générique pour tout agent IA
Peu importe l’outil ( Claude, Copilot en mode agent, Cursor, ou tout autre ) vous pouvez inclure cette règle dans vos instructions système ou fichiers de configuration de workspace :
Règle : Pour toute implémentation de fonctionnalité ou correction de bug,
tu dois produire un plan d'implémentation complet en utilisant le PLANNING_TEMPLATE
AVANT d'écrire du code. Le plan doit être validé par un humain avant de continuer.
Si la demande ne référence pas une issue avec :
- des critères d'acceptation explicites,
- des trust boundaries identifiées,
- des règles de validation des entrées,
alors demande ces informations plutôt que d'inventer.
Ne génère jamais de fonctionnalité non décrite dans l'issue de référence.
Les guardrails pour maintenir le cap
Pour empêcher l’agent de dériver hors périmètre :
- Contextualiser strictement : transmettez uniquement l’issue concernée, pas tout le backlog.
- Commenter les check-lists : les sections “hors périmètre” dans l’issue évitent l’invention par complétion.
- Limiter les outils disponibles : si votre agent peut modifier des fichiers de config système, il le fera => restreignez les permissions.
- Exiger une justification par changement : chaque modification de fichier non listée dans le plan doit être explicitée avant d’être acceptée.
- Automatiser la validation du plan : utilisez des scripts ou des étapes CI pour vérifier que le plan est complet et validé avant de permettre la génération de code.
- Valider le plan avant code : un humain doit approuver le plan d’implémentation avant que l’agent puisse générer du code. Pas de plan validé = pas de code.
- Revue humaine obligatoire : même avec un plan, la revue humaine reste indispensable pour valider les choix d’architecture et les contrôles de sécurité avant merge.
- Documenter les décisions : chaque choix d’implémentation doit être justifié dans le plan pour éviter les décisions arbitraires de l’agent.
- Suivre les changements de périmètre : si l’agent propose des changements hors périmètre, cela doit déclencher une alerte et nécessiter une nouvelle issue pour valider ces changements.
- Ne jamais faire confiance à l’agent pour deviner les exigences de sécurité : si elles ne sont pas explicitement définies dans l’issue, elles doivent être demandées et validées avant toute implémentation.
- Ne jamais faire confiance à l’agent pour deviner les frontières de confiance : si elles ne sont pas explicitement définies dans l’issue, elles doivent être demandées et validées avant toute implémentation.
- Ne jamais faire confiance à l’agent pour deviner les contrats d’entrée/sortie : si ils ne sont pas explicitement définis dans l’issue, ils doivent être demandés et validés avant toute implémentation.
- Ne jamais faire confiance à l’agent pour deviner les critères d’acceptation : si ils ne sont pas explicitement définis dans l’issue, ils doivent être demandés et validés avant toute implémentation.
- Ne jamais faire confiance à l’agent pour deviner les critères de testabilité : si ils ne sont pas explicitement définis dans l’issue, ils doivent être demandés et validés avant toute implémentation.
- Ne jamais faire confiance à l’agent pour deviner les considérations de sécurité : si elles ne sont pas explicitement définies dans l’issue, elles doivent être demandées et validées avant toute implémentation.
- Ne jamais faire confiance à l’agent pour deviner les dépendances : si elles ne
Règle absolue
Ne JAMAIS faire confiance à l'agent pour deviner les exigences fonctionnelles ou de sécurité. Si elles ne sont pas explicitement définies dans l'issue, elles doivent être demandées et validées avant toute implémentation.
Pas de plan validé = pas de code. Point.
L'agent est un exécuteur de plan — pas un inventeur de fonctionnalités ni de contrôles de sécurité.
Phase 3 : Revue de sécurité automatisée du code généré
L’agent a produit du code. Ce code a passé les tests fonctionnels. Il reste la question la plus importante : est-il sécurisé ?
La double passe de revue
On distingue deux passes complémentaires :
Passe 1 — Correction fonctionnelle :
- Le code respecte-t-il les critères d’acceptation de l’issue ?
- Les cas limites sont-ils couverts ?
- Les contrats d’entrée/sortie sont-ils honorés ?
Passe 2 — Sécurité :
- Chaque changement est-il mappé à une catégorie OWASP Top 10 / CWE / Whatever ?
- Les trust boundaries traversées sont-elles validées ?
- La hiérarchie des défenses est-elle respectée ?
La hiérarchie des défenses minimale à appliquer :
- rejet en entrée d’abord (validation stricte du type, du format, de la longueur),
- puis APIs strictes (paramétrage des requêtes, ORMs),
- puis encodage contextuel en sortie,
- et sanitisation uniquement en dernier recours.
Tout code qui commence par sanitiser sans rejeter en amont est un signal d’alarme.
Le prompt de revue de sécurité
Voici un template de prompt de revue utilisable avec n’importe quel LLM, ou intégrable dans un pre-commit hook via une API :
# Security Review Prompt
## Contexte
Revue de sécurité du diff suivant. L'issue de référence est : [ISSUE_CONTENT]
## Ce que tu dois analyser
### 1. Mapping OWASP Top 10
Pour chaque modification significative, identifie la ou les catégories OWASP
concernées parmi :
- A01 Broken Access Control
- A02 Cryptographic Failures
- A03 Injection (SQL, XSS, commande, LDAP...)
- A04 Insecure Design
- A05 Security Misconfiguration
- A06 Vulnerable and Outdated Components
- A07 Authentication and Identification Failures
- A08 Software and Data Integrity Failures
- A09 Security Logging and Monitoring Failures
- A10 Server-Side Request Forgery
### 2. Trust boundaries
- Quelles frontières de confiance sont traversées ?
- Les données sont-elles validées au point d'entrée de chaque frontière ?
- Peut-on tracer chaque donnée externe jusqu'à son point d'utilisation ?
### 3. Hiérarchie des défenses
- Y a-t-il des appels à des fonctions de sanitisation sans rejet préalable ?
- Les requêtes vers des systèmes tiers sont-elles paramétrées (pas de concaténation) ?
- L'encodage de sortie est-il contextuel (HTML, JSON, SQL) ?
### 4. Dépendances ajoutées
- Liste les nouvelles dépendances avec version.
- Vérifie si des CVEs connues existent pour ces versions.
### 5. Findings
Format de sortie pour chaque finding :
- Sévérité : CRITIQUE / ÉLEVÉE / MOYENNE / FAIBLE / INFO
- Catégorie OWASP : A0X
- Fichier et ligne : foo.py:42
- Description : explication claire du risque
- Recommandation : correction proposée
## Critère de blocage
Si au moins un finding CRITIQUE ou ÉLEVÉ est identifié, la revue est bloquante.
Le code ne peut pas être mergé sans remédiation et nouvelle revue.
Intégration dans la chaîne CI/CD
Ce prompt peut être exécuté :
- En pre-commit hook : via un script qui envoie le diff à l’API d’un LLM et parse le résultat.
- En step GitHub Actions / GitLab CI : déclenché sur chaque pull request, avec un commentaire automatique du rapport.
- Via des outils spécialisés : Semgrep, CodeQL, Snyk => qui peuvent être couplés à une analyse LLM pour la contextualisation.
La chaîne complète : du ticket au merge sécurisé
En combinant les trois phases, on obtient un workflow reproductible, indépendant de l’outil IA utilisé :
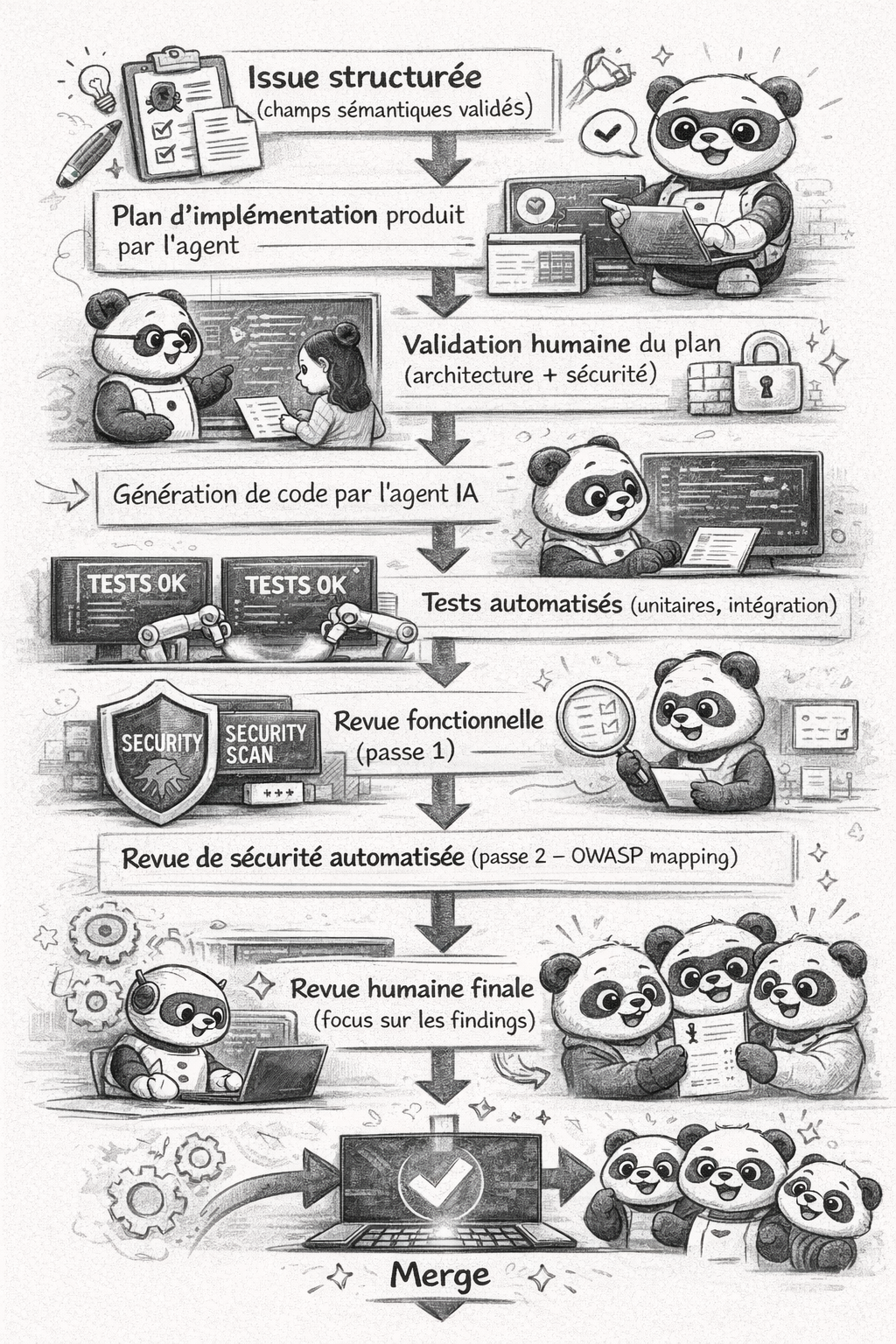
Ce workflow fonctionne que votre équipe utilise Claude Code, GitHub Copilot en mode agent, Cursor, Windsurf, ou un pipeline orchestré avec LangChain/LlamaIndex. Les artefacts (templates d’issues, PLANNING_TEMPLATE, security review prompt) sont des contrats entre l’humain et la machine, pas des configurations spécifiques à un outil.
À retenir
Quelques références pour aller plus loin
- OWASP Top 10 — la référence pour le mapping des vulnérabilités dans la revue de sécurité
- OWASP Application Security Verification Standard (ASVS) — pour structurer les exigences de sécurité dans les issues
- OWASP DevSecOps Guideline — référence pour l’intégration de la sécurité dans les pipelines CI/CD
- OWASP LLM Top 10 — les risques spécifiques aux LLMs dans la chaîne de développement
- Articles du blog — Le Vibe Coding : une approche de développement et ses risques — contexte et risques du développement assisté par IA
- Articles du blog — DevSecOps et Vibe Coding — intégration de la sécurité dans le cycle de développement IA
- Semgrep — analyse statique intégrable dans le pre-commit
- Gitleaks — détection de secrets dans les diffs avant commit
