~14 minutes
Je discutais récemment avec un responsable SOC qui réfléchissait comment gérer son premier incident impliquant un agent IA en production. Sa première question m’a fait sourire : « Quelle IP source je dois bloquer ? ». Sa deuxième, beaucoup moins : « Et là, je fais quoi du process ? Il n’y en a pas vraiment un… ».
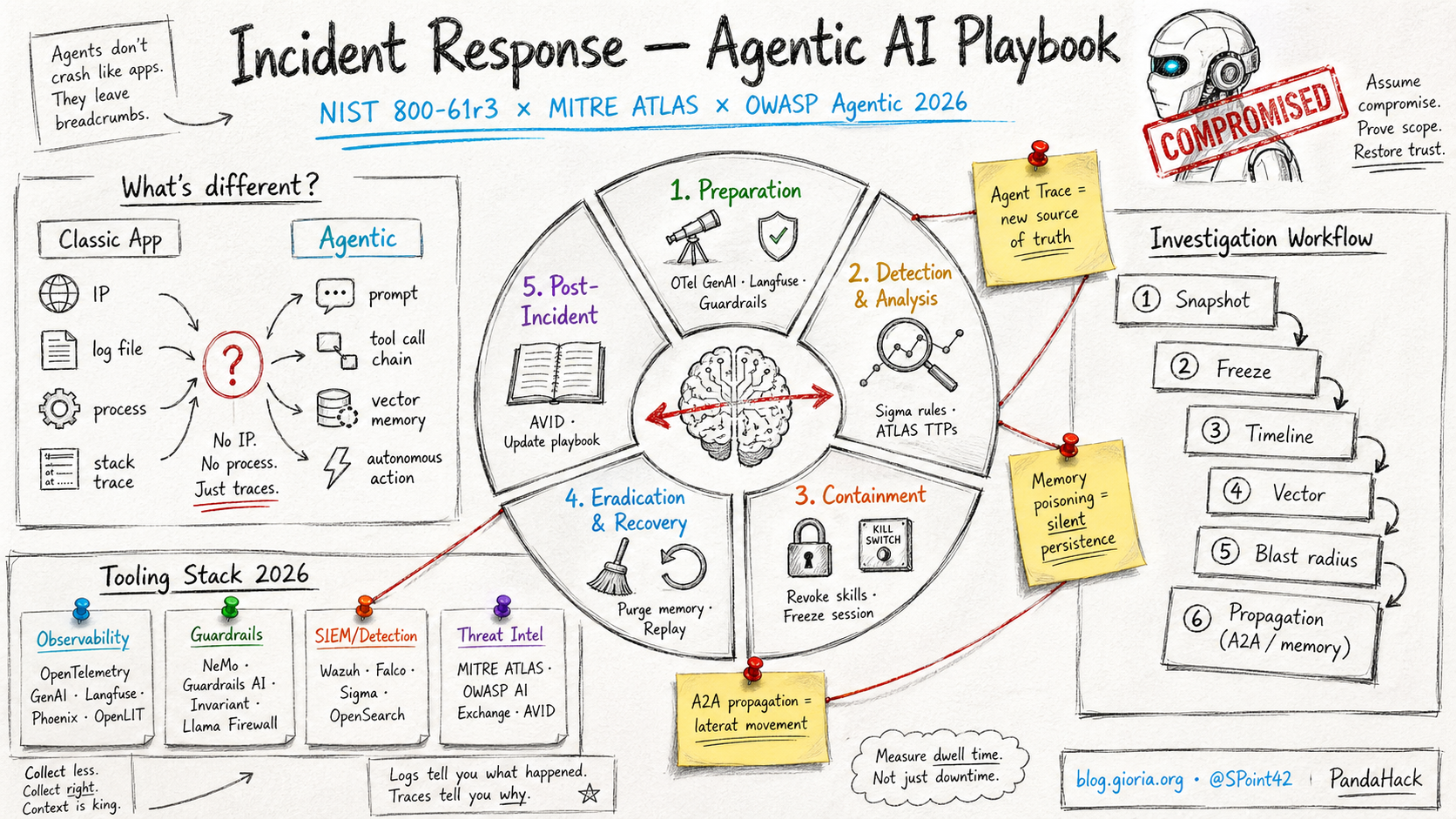
Voilà tout le problème. Un agent compromis ne ressemble en rien à un serveur web piraté : pas d’IP attaquante claire, pas de process à kill -9, pas de webshell à supprimer. À la place, une chaîne de tool calls non-déterministes, une mémoire vectorielle persistante, et des décisions autonomes prises au nom de votre organisation. Les playbooks IR que utilisés depuis quinze ans ne tiennent tout simplement plus.
Dans cet article, je vous propose un essai d’un guide pratique aligné sur le triptyque NIST SP 800-61r3 × MITRE ATLAS × OWASP Top 10 for Agentic Applications 2026, avec une stack open-source déployable rapidement, des règles Sigma concrètes, et un workflow d’investigation step-by-step. L’objectif : que votre CSIRT soit capable de répondre simplement à un incident agentique sans improviser.
Pourquoi l’IR classique casse face à un agent
Je constate qu’on essaie souvent de plaquer les réflexes web/SI sur les agents. Ça ne marche pas. Les six dimensions ci-dessous changent en profondeur.
| Dimension | Application classique | Système agentique |
|---|---|---|
| Surface d’attaque | Endpoints HTTP, paramètres | Prompts, outputs d’outils, mémoire, skills/MCP servers, agents pairs (A2A) |
| Artefact d’investigation | Log applicatif, dump mémoire | Agent trace (prompts + tool calls + décisions + contexte) |
| Persistance | Webshell, cron, service | Mémoire vectorielle empoisonnée, instruction injectée dans SOUL.md/MEMORY.md |
| Attribution | IP source, user-agent | Provenance du contenu déclencheur (qui a écrit le document RAG, qui a publié la skill ?) |
| Containment | iptables, kill process |
Revoke skill / désactiver MCP server / kill-switch guardrail / forcer human-in-the-loop |
| IOC | Hash, IP, domaine | Patterns de prompts, signatures sémantiques, hashes de skills, fingerprint MCP |
L’agent trace devient ta nouvelle source de vérité. Sans elle, tu n’as littéralement rien à analyser : un agent sans observabilité est une boîte noire qui prend des décisions au nom de ton entreprise.
Si tu veux te rafraîchir la mémoire sur les vecteurs d’entrée typiques, je te renvoie à mes articles sur les skills malveillantes ToxicSkills, la série Agentic AI Risks, et la propagation inter-agents A2A.
Le cadre de référence : NIST × ATLAS × OWASP Agentic 2026
Plutôt que de réinventer la roue, je m’appuie sur trois standards complémentaires.
- NIST SP 800-61 Revision 3 donne la colonne vertébrale du cycle IR (Preparation → Detection & Analysis → Containment/Eradication/Recovery → Post-Incident).
- MITRE ATLAS fournit la matrice TTPs spécifique IA (équivalent ATT&CK pour les systèmes ML/LLM).
- OWASP Top 10 for Agentic Applications 2026 (ASI01-ASI10) cartographie les risques métier propres aux agents.
Voici comment je les fais cohabiter en pratique :
| Phase NIST | Risques OWASP Agentic 2026 prioritaires | Tactiques MITRE ATLAS pertinentes |
|---|---|---|
| Preparation | ASI01 (Memory Poisoning), ASI02 (Tool Misuse), ASI07 (Cascading Failures) | AML.TA0000 Reconnaissance, AML.TA0002 Resource Development |
| Detection & Analysis | ASI03 (Privilege Compromise), ASI04 (Resource Overload), ASI06 (Identity Spoofing) | AML.T0051 LLM Prompt Injection, AML.T0053 LLM Plugin Compromise, AML.T0057 LLM Data Leakage |
| Containment / Eradication / Recovery | ASI05 (Goal Manipulation), ASI09 (Misaligned Behaviors) | AML.T0048 External Harms, AML.T0059 Erode ML Model Integrity |
| Post-Incident | ASI08 (Repudiation), ASI10 (Overreliance) | AML.TA0011 Impact, retours communautaires (AVID, OWASP AI Exchange) |
Le cadre n’est pas un dogme. C’est une grille de lecture qui me permet, en plein incident, de savoir où chercher, quoi nommer et comment mapper vers le langage commun de mes pairs.
Phase 1 - Préparation : ce qu’il FAUT déployer AVANT l’incident
Je le dis sans détour : 80% du succès d’une réponse agentique se joue avant l’incident. Si tu n’as pas instrumenté tes agents, tu auras une UI qui dit « ça a planté » et zéro élément pour reconstituer ce qui s’est passé.
1.1 Observabilité native agent
C’est le pilier numéro un. Tu dois tracer chaque prompt, chaque tool call, chaque décision, chaque accès mémoire, avec une rétention longue (30+ jours pour les traces complètes, 90+ jours pour les métadonnées).
On peut s’appuyer aujourd’hui sur les OpenTelemetry GenAI Semantic Conventions (attributs gen_ai.*), qui sont devenus le standard de facto en 2026 pour normaliser les traces LLM/agent. Côté outillage open-source, une stack de référence :
- Langfuse (self-hosted) — UI excellente pour explorer les traces, sessions et scoring. Mon premier choix pour l’investigation a posteriori.
- Arize Phoenix — fort sur l’évaluation et la détection de drift sémantique.
- OpenLIT — léger, OTel-natif, intègre bien avec un stack Grafana/Loki existant.
À tracer impérativement : prompt système final, prompt utilisateur, outputs de tools (entrée et sortie), identifiant de skill/MCP server invoqué, embeddings consultés, décision prise (action, abstention, escalade humaine).
1.2 Guardrails & policy-as-code runtime
Les guardrails ne sont pas qu’un filet de sécurité : ce sont aussi tes points d’observation et tes kill-switches en cas d’incident. Je recommande une combinaison :
- NVIDIA NeMo Guardrails — DSL Colang pour exprimer les politiques conversationnelles.
- Guardrails AI — validation structurée d’outputs, hub de validators.
- Invariant Labs — policy engine pour analyser les traces d’agents et détecter les violations de politique.
- Meta Llama Firewall —
PromptGuard 2,AlignmentCheck,CodeShieldpour filtrer prompts hostiles, dérives d’alignement et code dangereux généré.
Je détaille l’usage opérationnel des guardrails dans ma série dédiée — relis-la si besoin.
1.3 Detection & SIEM adapté aux agents
Ton SIEM doit ingérer les traces d’agents comme il ingère déjà tes logs réseau. Concrètement :
- Wazuh + custom decoders pour parser les exports JSON Langfuse/Phoenix.
- Falco avec règles eBPF spécifiques à l’exécution de tools (détection de processus enfant inattendus, accès filesystem hors sandbox, sorties réseau non whitelistées).
- OpenSearch + dashboards dédiés agents (anomalies de tool call rate, distribution des skills invoquées, pic de tokens consommés).
- SigmaHQ — la communauté ajoute progressivement des règles AI/LLM ; surveille le dossier
rules-emerging-threatset écris les tiennes.
1.4 Threat intelligence agentique
- MITRE ATLAS — la matrice de référence à intégrer dans ton TIP.
- OWASP AI Exchange — corpus collaboratif de contrôles et de mappings.
- AVID — AI Vulnerability Database — équivalent CVE pour les vulnérabilités de modèles et systèmes IA.
- Veille active sur les advisories Hugging Face, les blogs Snyk/Protect AI/HiddenLayer, et les CTI agentic.
1.5 Le « Agent Incident Bundle » - la checklist à cocher AVANT
Voici la liste des artefacts que qu’il faut pouvoir récupérer sous 5 minutes le jour J :
- Traces OTel complètes des sessions agent (≥ 30 jours)
- Snapshots périodiques de la base vectorielle / mémoire long-terme (≥ 7 jours, idéalement avec hash et signature)
- Logs guardrails (entrées bloquées, dérives, scores d’alignement)
- Inventaire signé des skills, MCP servers et outils déclarés (hash + version + provenance)
- Configuration des agents (system prompts, modèles, paramètres, identités)
- Liste des connexions A2A actives et permissions inter-agents
- Identités machine et tokens utilisés par chaque agent (rotation traçable)
- Procédure documentée de kill-switch par agent et par capability
Si tu coches moins de 5 cases sur 8, tu n’es pas prêt. Et tu le découvriras au pire moment.
Phase 2 - Détection & Analyse : reconnaître un agent compromis
Je distingue ici les signaux faibles qui doivent alerter ton SOC.
Signaux d’alerte prioritaires
| Sévérité | Signal observable | Tactique MITRE ATLAS associée |
|---|---|---|
| 🔴 Critique | Tool calling burst anormal (ex : > 10× la baseline en moins d’une minute) | AML.T0048 External Harms |
| 🔴 Critique | Sortie réseau d’un tool vers un domaine non whitelisté | AML.T0057 LLM Data Leakage |
| 🟠 Élevé | Dérive sémantique du prompt système (hash modifié, instructions ajoutées) | AML.T0051 LLM Prompt Injection |
| 🟠 Élevé | Score guardrail AlignmentCheck en chute brutale sur N sessions consécutives |
AML.T0059 Erode ML Model Integrity |
| 🟠 Élevé | Invocation d’une skill/MCP server jamais utilisée auparavant par cet agent | AML.T0053 LLM Plugin Compromise |
| 🟡 Moyen | Pattern de mémoire long-terme injectant des consignes opérationnelles | AML.T0057 + ASI01 Memory Poisoning |
| 🟡 Moyen | Hausse anormale de tokens consommés sur une session unique | AML.T0029 Denial of ML Service |
| 🟢 Faible | Échec répété d’un guardrail d’output sur un même type de requête | Indicateur de tentative d’évasion |
Phase 3 - Workflow d’investigation step-by-step
Quand l’alerte tombe, je suis le workflow ci-dessous. Il est conçu pour être tenable sous stress, en moins de 30 minutes pour un premier triage.
flowchart TD
A([🚨 ALERTE SOC]):::alert --> S1
S1["<b>1. Snapshot état</b><br/>mémoire + contexte<br/>+ hash skills"]:::preserve --> S2
S2["<b>2. Freeze session</b><br/>kill-switch guardrail<br/>HITL forcé"]:::contain --> S3
S3["<b>3. Reconstituer timeline</b><br/>Langfuse / Phoenix<br/>traces OTel GenAI"]:::analyze --> S4
S4{"<b>4. Vecteur d'entrée ?</b><br/>prompt · tool output<br/>mémoire · skill · A2A"}:::decide
S4 --> S5["<b>5. Évaluer rayon d'impact</b><br/>données lues<br/>actions externes<br/>sessions sœurs"]:::analyze
S5 --> S6["<b>6. Vérifier propagation</b><br/>mémoire long-terme<br/>agents pairs A2A"]:::propagate
S6 --> END([➡️ Phase 4 — Containment]):::done
classDef alert fill:#dc3545,stroke:#7a0e1c,stroke-width:2px,color:#fff,font-weight:bold
classDef preserve fill:#fff3cd,stroke:#b8860b,stroke-width:2px,color:#2d3748
classDef contain fill:#fd7e14,stroke:#a04400,stroke-width:2px,color:#fff
classDef analyze fill:#17a2b8,stroke:#0c525d,stroke-width:2px,color:#fff
classDef decide fill:#6f42c1,stroke:#3d2566,stroke-width:2px,color:#fff,font-weight:bold
classDef propagate fill:#e83e8c,stroke:#7a1f48,stroke-width:2px,color:#fff
classDef done fill:#28a745,stroke:#0f5223,stroke-width:2px,color:#fff,font-weight:bold
1. Snapshot l’état de l’agent. Avant tout : capturer la mémoire de travail, le contexte courant, la liste des outils actifs, le hash des skills chargées. Si tu redémarres un agent compromis sans snapshot, tu perds la scène de crime.
2. Geler la session - pas le process. Active le kill-switch côté guardrail (refus de tout output, mode HITL forcé) plutôt que de tuer brutalement le service. Ça te laisse le temps de raisonner sans perdre l’état.
3. Reconstituer la timeline. Ouvre Langfuse ou Phoenix sur la session incriminée. Question simple : quel est le premier prompt anormal et qui l’a produit (utilisateur, output de tool, contenu RAG, mémoire) ?
4. Identifier le vecteur d’entrée. Cinq candidats possibles :
- Prompt utilisateur direct (injection classique)
- Output d’un tool (injection indirecte via une page web, un email, un PR)
- Mémoire long-terme empoisonnée
- Skill ou MCP server compromis (cf. ToxicSkills)
- Message d’un agent pair (propagation A2A)
5. Évaluer le rayon d’impact. Quelles données ont été lues ? Quelles actions externes ont été déclenchées (emails envoyés, paiements, commits, tickets) ? Quelles autres sessions/utilisateurs partagent la même mémoire ou la même skill ?
6. Vérifier la propagation. C’est l’étape que tout le monde oublie. Si la mémoire long-terme est touchée, l’agent reste compromis même après reset de la session. Si tu es en architecture A2A, l’incident peut s’être propagé à des agents pairs : voir A2A03 - Cross-Agent Trust.
La règle d’or : un agent compromis n’est pas isolé. Mémoire partagée et orchestration A2A transforment chaque incident en mouvement latéral potentiel.
Phase 4 - Containment, Eradication, Recovery
Containment
- Révoquer immédiatement les API keys et identités machine de l’agent incriminé.
- Désactiver les skills / MCP servers suspects sur l’ensemble de la flotte (pas juste l’instance touchée).
- Basculer les agents critiques en mode HITL forcé : toute action externe nécessite validation humaine pendant la durée de l’investigation.
- Geler les écritures dans la base vectorielle partagée si une injection de mémoire est suspectée.
Eradication - la partie vraiment IA
C’est ici que ça devient inhabituel pour un SOC traditionnel.
- Purge ciblée de la mémoire vectorielle : identifier les embeddings injectés via la timeline d’écriture et les supprimer. Ne pas se contenter d’un reset global qui détruit aussi le contexte légitime.
- Régénérer les embeddings depuis les sources de vérité versionnées et signées. Si la source elle-même est compromise, remonter d’un cran.
- Reset des prompts système depuis un dépôt Git signé (jamais depuis l’instance live).
- Rotation complète des secrets accessibles à l’agent, comme pour tout incident d’identité.
Recovery
- Replay des sessions saines en environnement témoin pour valider que les guardrails durcis ne cassent pas le métier.
- Re-validation des politiques avec un set d’évals adversariales (prompts d’attaque connus, datasets ATLAS).
- Monitoring renforcé pendant 30 jours minimum : seuils Sigma plus stricts, sampling 100% des traces, revue humaine quotidienne des sessions à risque.
Phase 5 - Post-incident & lessons learned
Le post-mortem agentique a deux particularités à ne pas négliger.
- Documenter le prompt déclencheur exact (avec ses encodages, ses caractères Unicode, son contexte). C’est ton IOC le plus précieux pour les détections futures.
- Partager le TTP via AVID si la vulnérabilité concerne un modèle ou une plateforme tiers, ou via OWASP AI Exchange pour les contrôles. La communauté en a besoin, et tu en bénéficieras en retour.
À mettre à jour systématiquement après chaque incident :
- Règles Sigma (nouveaux patterns)
- Politiques guardrails (nouveaux validators)
- Threat model de l’agent (nouveau vecteur, nouveau composant à risque)
- Inventaire signé des skills/MCP (révocation, mise en quarantaine)
- Playbook IR lui-même (ce qui a manqué dans le bundle, ce qui a pris trop de temps)
Stack open-source recommandée
| Phase IR | Outil open-source | Rôle | Maturité |
|---|---|---|---|
| Préparation | OpenTelemetry GenAI semconv | Standard de traces agent | STABLE |
| Préparation | Langfuse · Phoenix · OpenLIT | Stockage et exploration des traces | PROD |
| Préparation | NeMo Guardrails · Guardrails AI · Invariant · Llama Firewall | Policy runtime + kill-switch | PROD |
| Détection | Wazuh + custom decoders | SIEM ingestion traces agent | PROD |
| Détection | Falco (eBPF) | Détection runtime exécution tools | PROD |
| Détection | SigmaHQ + règles agentiques | Format de règles partageables | EMERGING |
| Détection | OpenSearch + dashboards agents | Visualisation et threat hunting | PROD |
| Investigation | Langfuse / Phoenix UI | Timeline reconstruction | PROD |
| Threat Intel | MITRE ATLAS | Matrice TTPs IA | RÉFÉRENCE |
| Threat Intel | OWASP AI Exchange | Contrôles et mappings | RÉFÉRENCE |
| Threat Intel | AVID | Base de vulnérabilités IA | CROISSANCE |
Quelques références pour aller plus loin
- NIST SP 800-61 Revision 3 — Computer Security Incident Handling Guide
- OWASP Top 10 for Agentic Applications 2026
- MITRE ATLAS
- OWASP AI Exchange
- AVID — AI Vulnerability Database
- OpenTelemetry GenAI Semantic Conventions
- SigmaHQ — Generic Signature Format
- Articles internes : ToxicSkills · Série Agentic AI Risks · Série Guardrails · A2A Security A2A03
✓ À retenir 📌
✓ L'agent trace est ta nouvelle source de vérité : sans observabilité OTel GenAI native, tu ne peux ni détecter, ni investiguer, ni apprendre d'un incident agentique.
✓ Cadre hybride NIST × ATLAS × OWASP Agentic 2026 : adopte ce langage commun pour cartographier signaux, vecteurs et phases IR sans réinventer la roue.
✓ 80% du succès se joue en phase Préparation : observabilité, guardrails, SIEM agentique, threat intel et un « Agent Incident Bundle » prêt à être saisi en 5 minutes.
✓ Geler la session, pas le process : le kill-switch côté guardrail préserve la scène de crime, alors qu'un `kill -9` détruit l'état nécessaire à l'investigation.
✓ Cinq vecteurs d'entrée à interroger systématiquement : prompt utilisateur, output de tool, mémoire long-terme, skill/MCP, agent pair (A2A). Aucun n'est par défaut.
✓ La mémoire vectorielle est la nouvelle persistance : un agent compromis reste compromis tant qu'on n'a pas purgé et re-signé les embeddings depuis une source de vérité.
✓ Pense propagation : mémoire partagée et orchestration A2A transforment chaque incident en mouvement latéral potentiel ; vérifie agents pairs et sessions sœurs.
✓ Partage tes TTP via AVID et OWASP AI Exchange : la communauté IR agentique se construit collectivement, et l'écosystème est encore jeune.
💡 Un agent IA en production sans plan de réponse à incident, c'est un copilote sans siège éjectable.